I am preparing for a talk on the controversy surrounding JNC-8 and came across a post on KevinMD.com by an author of a Cochrane systematic review that aimed to quantify the effects of antihypertensive drug therapy on mortality and morbidity in adults with mild hypertension (systolic blood pressure (BP) 140-159 mmHg and/or diastolic BP 90-99 mmHg) and without cardiovascular disease. This is an important endeavor because the majority of people we consider treating for mild hypertension have no underlying cardiovascular disease.
David Cundiff, MD in his KevinMD.com post made this statement:
The JNC-8 authors simply ignored a systematic review that I co-authored in the Cochrane Database of Systematic Reviews that found no evidence supporting drug treatment for patients of any age with mild hypertension (SBP: 140-159 and/or DBP 90-99) and no previous cardiovascular disease, diabetes, or renal disease (i.e., low risk).
Let’s see if you agree with his assessment of the findings of his systematic review.
As is typical for a Cochrane review the methods are impeccable so we don’t need to critically appraise the review and can review the results. The following images are figures from the review. Examine them and then I will discuss my take on the results.

Mortality results
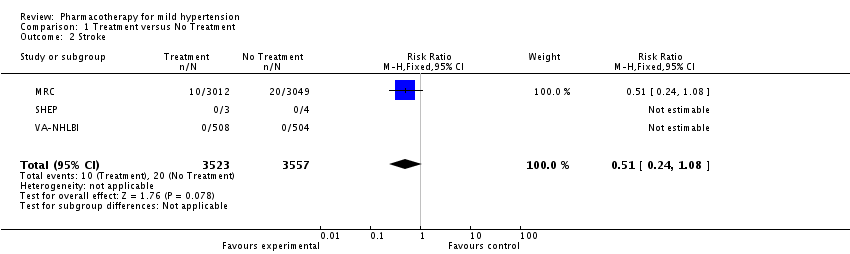
Stroke results

Coronary Heart Disease results

Adverse Effects
If you just look at the summary point estimates (black diamonds) you would conclude the treatment of mild hypertension in adults without cardiovascular disease has no effect on mortality, stroke and coronary heart disease but greatly increases withdrawal from the study due to adverse effects. But you are a smarter audience than this. The real crux is in the studies listed and examination of the confidence intervals.
Lets examine stroke closely. 3 studies were included that examined the treatment of mild hypertension on stroke outcomes. Two of the studies had no stroke outcomes at all. The majority of the data came from one study. The point estimate of effect was in fact a reduction of stroke by 49% but the confidence interval included 1.0 so not statistically significant. But the confidence interval ranged from 0.24-1.08- a potential 76% reduction in stroke up to an 8% increase. I would argue that a clinically important effect (stroke reduction) is very possible and had the studies been higher powered we would have seen a statistically significant reduction also. I think to suggest no effect on stroke is misleading. The same can be said for mortality.
Finally, what about withdrawals due to adverse effects. Only 1 study provided any data. It has an impressive risk ratio of 4.80 (almost 5 fold increased risk of stopping the drugs due to adverse effects). But the absolute risk increase is only 9% (NNH 11). We are not told what these adverse effects are to know if they were clinically worrisome or just nuisances for patients.
So, I don’t agree with Dr. Cundiff’s assessment that there is no evidence supporting treatment. I think the evidence is weak but there is no strong evidence to say we shouldn’t treat mild hypertension. The confidence intervals include clinically important benefits to patients. More studies are needed but will not be forthcoming. Observational data supports treating this group of patients and may have to be relied upon in making clinical recommendations.