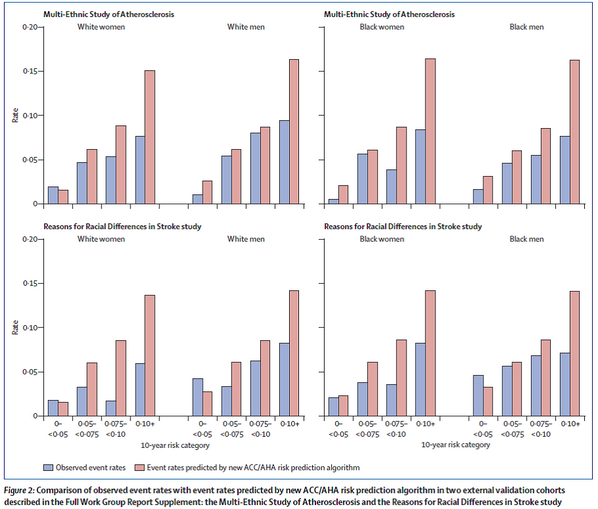
2 papers got published this week to further validate the pooled risk equations developed for the ACC/AHA Cholesterol Guidelines.
Muntner and colleagues used the REGARDS participants to assess the calibration and discrimination of the pooled risk equations. This study had potential as it oversampled patients from the stroke belt. This is important because the Pooled Risk Equations were developed to overcome the limitations of the Framingham tool (mainly its lack of minorities). I have a real problem with this study because the pooled risk equations estimate 10 yr risk of CHD and stroke and this study only has 5 yrs of follow-up for the REGARDS participants. I don’t think their estimates of calibration and discrimination are valid. Risk of CHD and stroke should increase over time so event rates could change with 5 more years of follow-up. The important thing this paper adds is the reminder that observational studies often lack active surveillance. Most observational studies rely on self report of outcomes and obviously silent events would be missed by the patient as would events for which the patient didn’t seek evaluation. Muntner and colleagues also used Medicare claims data to identify events not detected through routine cohort follow-up and found 24% more events. This is a useful lesson from this study.
In a more useful study Kavousi and colleagues compared 3 risk prediction tools (pooled risk equations, Framingham, and SCORE) using the Rotterdam Study, a prospective population-based cohort of persons aged 55 yrs and older. This cohort does have 10 yrs of follow-up.

This figure shows that at each level of risk the pooled risk equations overestimated risk, though less so in women.

This figure shows the proportion of patients for whom treatment is recommended (red bars), treatment should be considered (yellow bars), and no treatment is recommended (green bars). As you can see the new risk tool leads to the large majority of men “needing treatment” compared to previous guidelines (ATP III) and the current European guidelines (ESC).

Finally, this figure shows the calibration curves and the calibration was not good. The blue dots should lie right upon the red line for good calibration. Furthermore, the c-statistic is 0.67 (a measure of discrimination which means the tool can differentiate diseased from nondiseased patients. A c-statitic above 0.7 is considered moderate to good. The closer to 1 the better).
Why might the pooled risk equations overestimate risk? Maybe they don’t if you believe the Muntner study. It could just be a problem with the lack of active surveillance in the cohort studies used to validate the tool. Or they really do overestimate risk because they aren’t accurate or maybe more contemporary patients receive better therapies that improve overall health or maybe the baseline risk characteristics of the validation cohorts just differ too much from the development cohorts.
I am still not sold on the new pooled risk equations but they might not be much better than what we have been using based on the Kavousi study (Framinham also overpredicted risk and had poor calibration). I think we need more study and tweaking of the tool or we use the tool as is and focus more on cardiovascular risk reduction (with exercise, diet, tobacco cessation, diabetes and HTN control) and don’t focus so much on starting a statin right away.
The Mayo Clinic has a nice patient decision aid that you can use to help patients decide if a statin is right for them: http://statindecisionaid.mayoclinic.org/index.php/site/index