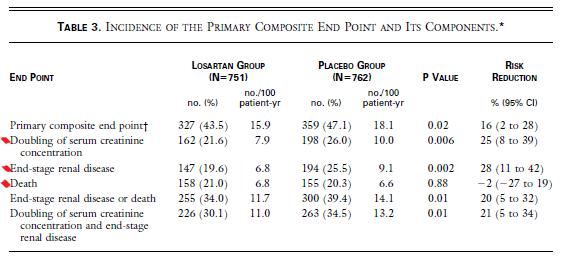
When I reflect on what I do each day as a physician it occurs to me that I use EBM skills very commonly. Here is a sampling:
- I think about and assess pretest probability a lot
- I think about choosing appropriate tests a lot
- I apply information from studies a lot. I weigh risks and benefits of therapies. I think about patient context. I try to incorporate patient values and desires as much as possible.
- I search for information following the Haynes’ 6S approach
- I critically appraise primary studies and systematic reviews each week (not daily)
- I make calculations because studies don’t always put information in the format I want
- I have discussions with patients about the above issues
I am sure I am missing a lot of what I do that falls under “EBM”. I am revamping an introductory course in EBM I teach to 2nd medical students for the upcoming semester. It has been relegated to “just teach them enough to get a good score on Step 1”. Thankfully, I have a fuller online version that they will take during their scholarly time in the 3rd year so all is not lost. To make me feel better, I view the crash course I am teaching them this upcoming semester as scaffolding so that they can better understand my full online course. You can look at and use the materials I will use in the crash course in the tab above labeled “Online Teaching Resources” (I just realized still have to add a few items that the students will use).
We spend so much time in the 1st 2 years of medical school teaching about things that I honestly never ever use but yet what I use daily gets short shrift. Why is that? Are EBM skills not important? Is it assumed they are easy to develop later in one’s career on one’s own (they aren’t)? Is it just kicking the can down the road assuming in residency these skills will be learned? Or during the clerkships?
I for one wish none of this material was on Step 1. I think it’s too early. Furthermore, I am so sick of my course evaluations including statements like “Taught too much stuff that wasn’t on step 1”. I think you need some clinical knowledge to really learn EBM, but more importantly, to understand its importance. EBM type questions should get greater prominence on Step 2 and even more prominence on step 3 exams. One or 2 questions only reinforces the perceived lack of importance of EBM. EBM should have just as many questions as any of the specialties and each test should have more questions to reinforce that these skills are important and will be used. Maybe Santa will grant me that wish one of these years. (I am keeping my fingers crossed I get onto the NBME committee that writes the EBM questions. Maybe I can convince them of my plan)