I came across this blog post by Buster Benson describing cognitive biases and thought I would share it here. There is a great graphic at the bottom of his post. Amazing how many biases there are. Enjoy.
Tag Archives: bias
3 Pronged Approach to Reading a Clinical Study
There has been an interesting discussion on how to critically appraise a study on the Evidence-Based Health listserv over the last day. It is interesting to see different opinions on the role of critical appraisal.
One important thing to remember as pointed out by Ben Djulbegovic is that critical appraisal relies on the quality of reporting as these 2 studies showed: http://www.ncbi.nlm.nih.gov/pubmed/22424985 and http://www.ncbi.nlm.nih.gov/pmc/articles/PMC313900/ . The implications are important but difficult for the busy clinician to deal with.
There are 3 questions you should ask yourself as you read a clinical study:
- Are the findings TRUE?
- Are the findings FREE OF THE INFLUENCE OF BIAS?
- Are the findings IMPORTANT?
The most difficult question for a clinician to answer initially is if the findings are TRUE. This question gets at issues of fraud in a study. Thankfully major fraud(ie totally fabricated data) is a rare occurrence. Totally fraudulent data usually gets exposed over time. Worry about fraudulent data when the findings seem too good to be true (ie not consistent with clinical experience). Usually other researchers in the area will try to replicate the findings and can’t. There are other elements of truth that are more subtle and occur more frequently. For example, did the authors go on a data dredging expedition to find something positive to report? This would most commonly occur with post hoc subgroup analyses. These should always be considered hypothesis generating and not definitive. Here’s a great example of a false subgroup finding:
The Second International Study of Infarct Survival (ISIS-2) investigators reported an apparent subgroup effect: patients presenting with myocardial infarction born under the zodiac signs of Gemini or Libra did not experience the same reduction in vascular mortality attributable to aspirin that patients with other zodiac signs had.
Classical critical appraisal, using tools like the Users’ Guides, is done to DETECT BIASES in the design and conduct of studies. If any are detected then you have to decide the degree of influence that the bias(es) has had on the study results. This is difficult, if not impossible, to determine with certainty but there are studies that estimate the influence of various biases (for example, lack of concealed allocation in a RCT) on study outcomes. Remember, most biases lead to overestimate of effects. There are 2 options if you detect biases in a study: 1) reduce the “benefit” seen in the study by the amounts demonstrated in the following table and then decide if the findings are still important enough to apply in patient care, or 2) discard the study and look for one that is not biased.
This table is synthesized from findings reported in the Cochrane Handbook (http://handbook.cochrane.org/chapter_8/8_assessing_risk_of_bias_in_included_studies.htm)
BIAS EXAGGERATION OF EFFECT OF BENEFIT
Lack of randomization 25% (-2 to 45%)
Lack of allocation concealment 18% (5 to 29%)
Lack of blinding 9% (NR)
Finally, if you believe the findings are true and are free of significant bias, you have to decide if they are CLINICALLY IMPORTANT. This requires clinical judgment and understanding the patient’s baseline risk of the bad outcome the intervention is trying to impact. Some people like to calculate NNTs to make this decision. Don’t just look at the relative risk reduction and be impressed because you can be misled by this measure as I discuss in this video: https://youtu.be/7K30MGvOs5s
Evidence Based Medicine Is Not In Crisis! Part 1
Trisha Greenhalgh and colleagues wrote an opinion piece in BMJ recently lamenting (or perhaps exalting) that the EBM movement is in crisis for a variety of reasons. I don’t agree with some of the paper and I will outline in a series of posts why I disagree.
When most people complain about EBM or discuss its shortcomings they usually are not basing their arguments on the current definition of EBM. They use the original definition of EBM in which EBM was defined as the conscientious, explicit, and judicious use of current best evidence in making decisions about the care of individual patients. This definition evolved to “the integration of best research evidence with clinical expertise and patient values. Our model acknowledges that patients’ preferences rather than clinicians’ preferences should be considered first whenever it is possible to do so“.
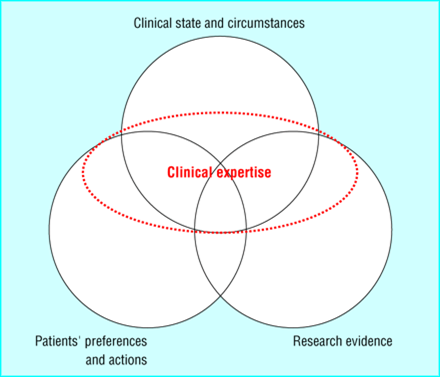
The circles in this diagram are ordered based on importance- with patient preferences and actions being most important and research evidence being the least important when practicing EBM. You can see that clinical expertise is used to tie it all together and decide on what should be done, not what could be done.
Back to the Greenhalgh paper. Her first argument is that there has been distortion of the evidence brand. I agree. It seems everyone wants to add the “evidence based” moniker to their product. But she argues beyond just a labeling problem. She argues that the drug and medical device industry is determining our knowledge because they fund so many studies. Is this the fault of EBM? Or should funding agencies like the NIH and regulatory agencies like the FDA be to blame? I think the latter. Industry will always be the main funder of studying their product and they should be. They should bear the cost of getting product to market. That is their focus. To suggest they shouldn’t want to make profit is just ridiculous.
The problem arises in what the FDA (and equivalent agencies in other countries) allows pharma to do. Greenhalgh points out the gamesmanship that pharma plays when studying their drug to get the outcomes they desire. I totally agree with what she points out. Ample research proves her points. But it’s not EBM’s fault. The FDA should demand properly conducted trials with hard clinical outcomes be the standard for drug approval. Companies would do this if they had to to get drug to the market. I also blame journal editors who publish these subpar studies. Why do they? To keep advertising dollars? The FDA should also demand that any study done on a drug be registered and be freely available and published somewhere easily accessible (maybe clinical trials.gov). Those with adequate clinical and EBM skills should be able to detect when pharma is manipulating drug dosages, using surrogate endpoints, or overpowering a trial to detect clinically insignificant results. I look at this as a positive for continuing to train medical students and doctors in these skills.
Research has shown that industry funded studies overestimate the benefits of their drugs by maybe 20-30%. A simple way to deal with this is to take any result from an industry funded study and to reduce it by 20-30%. If the findings remain clinically meaningful then use the drug or device.
I agree with Greenhalgh that current methods to assess study biases are outdated. The Users’ Guides served their purpose but need to be redone to detect the subtle gamesmanship going on in studies. Future and current clinicians need to be trained to detect these subtle biases. Alternatively, why can’t journals have commentaries about every article similar to what BMJ Evidence Based Medicine and ACP Journal Club do. This could then be used to educate journal users on these issues and put the results of studies into perspective.
Useful diagram to teach basic EBM concepts
Dr. La Rochelle published an article in BMJ EBM this month with a very useful figure in it (see below). It is useful because it can help our learners (and ourselves) remember the relationship between the type of evidence and its believability/trustworthiness.

Lets work through this figure. The upright triangle should be familiar to EBM aficionados as it is the typical hierarchy triangle of study designs, with lower quality evidence at the bottom and highest quality at the top (assuming, of course, that the studies were conducted properly). The “Risk of Bias” arrow next to this upright triangle reflects the quality statement I just made. Case reports and case series, because they have no comparator group and aren’t systematically selected are at very high risk of bias. A large RCT or systematic review of RCTs is at the lowest risk of bias.
The inverted triangle on the left reflects possible study effects, with the width of the corresponding area of the triangle (as well as the “Frequency of Potential Clinically relevant observable effect arrow) representing the prevalence of that effect. Thus, very dramatic, treatment altering effects are rare (bottom of triangle, very narrow). Conversely, small effects are fairly common (top of triangle, widest part).
One way to use this diagram in teaching is to consider the study design you would choose (or look for) based on the anticipated magnitude of effect. Thus, if you are trying to detect a small effect you will need a large study that is methodologically sound. Remember bias is a systematic error in a study that makes the findings of the study depart from the truth. Small effects seen in studies lower down the upright pyramid are potentially biased (ie not true). If you anticipate very large effects then observational studies or small RCTs might be just fine.
An alternative way to use this diagram with learners is to temper the findings of a study. If a small effect is seen in a small, lower quality study they should be taught to question that finding as likely departing from the truth. Don’t change clinical practice based on it, but await another study. A very large effect, even in a lower quality study, is likely true but maybe not as dramatic as it seems (ie reduce the effect by 20-30%).
I applaud Dr. La Rochelle for developing a figure which explains these relationships so well.
Why Can’t Guideline Developers Just Do Their Job Right????
I am reviewing a manuscript about the trustworthiness of guidelines for a prominent medical journal. I have written editorials on this topic in the past (http://jama.jamanetwork.com/article.aspx?articleid=183430 and http://archinte.jamanetwork.com/article.aspx?articleid=1384244). The authors of the paper I am reviewing reviewed the recommendations made by 3 separate medical societies on the use of a certain medication for patients with atrial fibrillation. The data on this drug can be summarized as follows: little benefit, much more harm. But as you would expect these specialists recommended its use in the same sentence as other safer and more proven therapies. They basically ignored the side effects and only focused on the minimal benefits.
Why do many guideline developers keep doing this? They just can’t seem to develop guidelines properly. Unfortunately their biased products have weight with insurers, the public, and the legal system. The reasons are complex but solvable. A main reason (in my opinion) is that they are stuck in their ways. Each society has its guideline machine and they churn them out the same way year after year. Why would they change? Who is holding them accountable? Certainly not journal editors. (As a side note: the journals that publish these guidelines are often owned by the same subspecialty societies that developed the guidelines. Hmmmm. No conflicts there.)

The biggest problem though is conflicts of interest. There is intellectual COI. Monetary COI. Converting data to recommendations requires judgment and judgment involves values. Single specialty medical society guideline development panels involve the same types of doctors that have shared values. But I always wonder how much did the authors of these guidelines get from the drug companies? Are they so married to this drug that they don’t believe the data? Is it ignorance? Are they so intellectually dishonest that they only see benefits and can’t understand harm? I don’t think we will ever truly understand this process without having a proverbial fly on the wall present during guideline deliberations.
Until someone demands a better job of guideline development I still consider them opinion pieces or at best consensus statements. We need to quit placing so much weight on them in quality assessment especially when some guidelines, like these, recommend harmful treatment.
