In this installation I want to jump ahead in Greenhalgh’s paper to address her last cause of the EBM crisis: “Poor fit for multimorbidity“. Not to worry, I will come back in a future post to cover the remaining “problems” of EBM.
I concur with Greenhalgh that individual studies have limited applicability by themselves in a vacuum to patients with multimorbidity. Guidelines don’t help a they also tend to be single disease focused and developed by single disease -ologists. So is EBM at fault here again? Of course not. EBM skills to the rescue.
The current model of EBM demonstrated below contains 2 important elements: clinical state and circumstances and clinical experience.
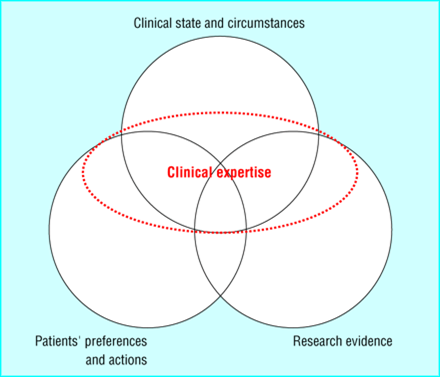
Clinical state and circumstances largely refers to the patient’s comorbidities, various other treatments they are receiving, and the clinical setting in which the patient is being seen. Thus, the EBM paradigm is specifically designed to deal with multimorbidity. Clinical expertise is used to discern what impact other comorbidities have on the current clinical question under consideration. and, along with the clinical state/circumstance, helps us decide how to apply a narrowly focused study or guideline in a multimorbid patient. Is this ideal? No. It would be nice if we had studies that included patients with multiple common diseases but we have to treat patients with the best available evidence that we have.