Del Fiol and colleagues published a systematic review of studies examining the questions raised and answered by clinicians in the context of patient care. The studies they examined used several methodologies including after-visit interviews, clinician self-report, direct observation, analysis of questions submitted to an information service, and analysis of information resource search logs. Each of these methodologies has their pros and cons. I’ll review their findings following the 4 questions that they asked.
How often do clinicians raise clinical questions? On average, clinicians ask 1 question for every 2 patients (range 0.16-1.85).
How often do clinicians pursue questions they raise? On average, they only pursued 47% (range 22-71%).
How often do clinicians succeed at answering the questions they pursue? They were pretty successful when they decided to pursue an answer: 80% of the time they were able to answer the question. Interestingly, clinicians spent less than 2-3 minutes seeking an answer to a specific question. They were clearly choosing questions that could be answered fairly quickly when they decided to pursue the answer to a question.
What types of questions were asked? Overall, 34% of questions were related to drug treatment while 24% were related to the potential causes of a symptoms, physical finding, or diagnostic test finding.
I find 3 other findings (from the Box in the manuscript) interesting:
- Most questions were pursued with the patient still in the practice (not sure if the clinicians searched in front of the patient or left the room- more about this later)
- Most questions, as you would expect, are highly patient-specific and nongeneralizable. This is unfortunate for long-term learning.
- Also unfortunately, clinicians mainly used paper and human resources (more on this in a minute)

From ticklemeentertainment.com
Even though Del Fiol examined barriers to answering questions I refer to another study by Cook and colleagues that more closely examined barriers to answering clinical questions at the point of care. Cook did focus groups with a sample of 50 primary care and subspecialist internal medicine and family medicine physicians to understand barriers and factors that influence point of care learning/question answering. Of course the main barrier is time. This study was done in late 2011 into early 2012 and included a wide range of ages of participants. With the resources available on both the desktop and handheld devices this barrier should be declining, especially when you consider the most common question clinicians ask is about drug treatment.
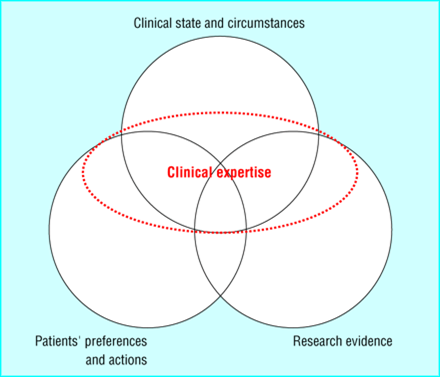
Physicians frequently noted patient complexity as a barrier. Complex patients require more time and often lead to more complex questions that are harder to answer with many resources. Almost all guidelines and studies are focused on single disease patients. Multimorbidity is rarely covered. Thus many answers will likely rely on clinical expertise and judgment. This is where using human resources is likely to occur. I bet few of us question how up to date our colleagues are that we ask questions of.
Interestingly, Cook’s study participants identified the sheer volume of information as a barrier. As a result, these physicians used textbooks more than electronic resources. I wonder if they understand that a print textbook is at least a year out of date by the time it hits market. How often do they update their textbooks? (likely rarely…just look at a private practice doctor’s bookshelf and you will often see books that are at least 2 or more editions out of date).
Finally, the physicians in Cook’s study felt that searching for information in front of the patient might “damage the patient-physician relationship or make patients uncomfortable.” They couldn’t be more wrong. Patients actually like when we look things up in front of them. I always do this and I tell them what I am looking up and admit my knowledge limitation. I show them what I found so they can participate in decision making. No one can know everything and patients understand that. I would be wary of a physician who doesn’t look something up.
So, how should a busy clinician go about answering clinical questions?
- You must have access to trustworthy resources. 2 main resources should suffice: a drug resource (like Epocrates or Micromedex- both are free and available for smartphones and desk tops) and what Haynes labels as a “Summary” (Dynamed or UpToDate). I leave guidelines out here (even though they are classified as a “Summary” resource) because most guidelines are too narrowly focused and many are not explicit enough in their biases.
- Answer the most important questions (most important to the patient #1 and then most important to improving your knowledge #2). If the above resources can’t answer your question and you must consult a colleague challenge them to support their opinion with data. You will learn something and likely they will too.
- Answer the questions you can in the available time. Many questions should be able to be answered in 5 min or less using the above resources. You are more likely to search for an answer to a question while the patient is in your office than waiting until the end of the day (the above cited studies can attest to that).
- Be creative in answering questions. I saw a great video by Paul Glasziou (sorry can’t remember which of his videos it was to link) where he discussed a practice-based journal club. Your partners likely are developing similar questions as your are. This is how he recommends organizing each journal club session: step 1 (10 min) discuss new questions or topics to research, step 2 (40 min) read and appraise (if needed) a research paper for last week’s problem, and step 3 (10 min) develop an action plan to implement what you just learned. This is doable and makes your practice evidence-based and feel somewhat academic. If you follow the Haynes hierarchy and pick the right types of journal articles (synopses and summaries) you can skip the appraisal part and just use the evidence directly.
Ultimately you have to develop a culture of answering questions in your practice. It has to be something you truly value or you won’t do it. Resources are available to answer questions at the point of care in a timely fashion. At some point we have to stop making excuses for not answering clinical questions.